


K-means algoritması veya K-means kümeleme , makine öğrenimindeki en basit ve en yaygın denetimsiz ve kümeleme algoritmalarından biridir . K-means kümeleme algoritması, belirli etiketleri olmayan verilerdeki kategorileri bulmak için kullanılır. şu verilerde ne tür kategorilerin ve düzenliliklerin bulunduğuna ilişkin iş varsayımlarını doğrulamak veya karmaşık veri kümelerinde bilinmeyen kategorileri belirlemek için kullanılabilir. Bu yazıda öncelikle K-means nedir sorusuna cevap verilmiş ardından Python da K-means uygulama eğitimi basit ve adım adım anlatılmıştır.
K-Means, en yaygın kullanılan veri kümeleme algoritmalarından biridir. K-ortalamalarda, sabit eylemleri tekrarlayarak ve Norm, Ortalama ve Argmin gibi fonksiyonları kullanarak, her bir küme için yüksek doğruluk ve düşük eylemsizliğe sahip merkezler bulmak mümkündür .
K-means algoritmasındaki amaç, bir kümedeki noktalar (veriler) arasındaki mesafeyi en aza indirmektir. K-means, bir kümeye bir nokta atamak için mesafelerin hesaplandığı merkez tabanlı veya mesafe tabanlı bir algoritmadır. K-ortalamalarda, her kümenin bir merkezi vardır. K-means algoritmasının temel amacı, karşılık gelen kümenin merkezi ile noktalar arasındaki mesafelerin toplamını en aza indirmektir.
K-means algoritmasını uygulama adımları nelerdir?
Genel olarak, K-means algoritmasını uygulama adımları aşağıdaki gibidir:
- Küme sayısının belirlenmesi (K)
- Küme merkezlerinin koordinatları olarak verilerden K rasgele sayı seçme
- Tüm noktaların (verilerin) en yakın küme merkezine atanması
- Her bir kümenin verilerinin ağırlıklı ortalamasını merkez olarak seçmek
- Durdurma kriteri sağlanana kadar 3. ve 4. adımları tekrarlayın.
K-means algoritması için durdurma kriterleri nelerdir?
Temel olarak, K-means algoritmasının yineleme döngüsünü durdurmak için üç durdurma kriteri kullanılabilir. Bu üç kriter aşağıda sıralanmıştır:
- Yeni oluşturulan kümelerin merkezleri değişmez.
- Noktalar (veriler) aynı kümede kalır ve veriler için küme üyeliği değişmez.
- Tekrar sayısı, maksimum (belirtilen) tekrar sayısına ulaşır.
K-means algoritmasının matematiksel ilişkisi nedir?
Bu algoritma matematiksel dilde şu şekilde olacaktır:
)⩾1
Makalenin devamında K-means nedir, Python’da bu algoritmanın implementasyonu anlatılmaktadır. Ancak bundan önce, bu alanla ilgilenenler için bir dizi ders dışı veri madenciliği ve makine öğrenimi kursu tanıtıldı.
K-means’ın Python’da uygulanması
Makalenin bu bölümünde K-means nedir, Python’da algoritmasını uygulama eğitimi adım adım sunulmaktadır. İlk adım, kullanılan kütüphaneleri çağırmaktır.
Python’da K-means algoritmasını uygulamak için kitaplıkları çağırma
K-means algoritmasının Python’da uygulanması, numpy ve Matplotlib kitaplıklarını kullanır, bu nedenle programlama ortamına girmeli ve bu kitaplıkları çağırmalısınız:
Bir sonraki adımda, K-ortalamalarını çalıştırmak için sentetik veriler tanımlanmalıdır. Bu çalışma bu nedir makalesinin bu bölümünün devamında yapılmıştır.
Python’da K-means algoritmasını uygulamak için yapay veriler oluşturma
Python’da K-means algoritmasını uygulamak için gerekli kütüphaneler çağrıldıktan sonra, şu algoritmasının gerçeklenmesinden elde edilen sonuçların gerçek değerlerle karşılaştırılabilmesi için küme merkezleri belirlenmiş bir veri seti oluşturulmalıdır.
şu belirli küme merkezleriyle sentetik veri üretmeye yönelik kodlar aşağıdaki gibidir:
Yukarıdaki kodlarda oluşturulan CreateDataset fonksiyonunda, her bir giriş merkezi etrafında rastgele bir dizi nD verisi oluşturulmakta ve çıktıda döndürülmektedir.
Yapay veri oluşturma işlevini çağırma
CreateDataset işlevini çağırmak aşağıdaki gibidir:
Yukarıdaki kodda, nD, Cs ve S dahil olmak üzere CreateDataset işlevinin giriş parametreleri tanımlanır ve başlatılır. Daha sonra CreateDataset fonksiyonu çağrılır ve tanımlanan değişkenler bu fonksiyona girdi olarak iletilir. İşlevi yürüttükten sonra, gerekli veriler X dizisinde saklanacaktır.
Oluşturulan verilerin görselleştirilmesi
Oluşturulan verileri görüntülemek ve görselleştirmek için veriler bir dağılım grafiği olarak çizilebilir:
Yukarıdaki kodlarda plt.scatter komutunun iki kez kullanıldığına dikkat edilmelidir. plt.scatter’ın ilk çağrısında X matris verilerinin dağılımı, ikinci çağrısında ise kümelerin merkezleri çizilir. Bu makalede, Python’da K-means algoritmasını uygulamak için iki boyutlu veriler kullanılmıştır. Bu çalışma, hesaplamaları basitleştirmek ve verileri grafikte gösterme imkanı sağlamak amacıyla yapılmıştır. CeateDataset işlevinde X boyutları değiştirilerek daha yüksek boyutlu veriler oluşturulabilir. Yukarıdaki kodların dağıtım şeması çıktıda şu şekilde yazdırılır:

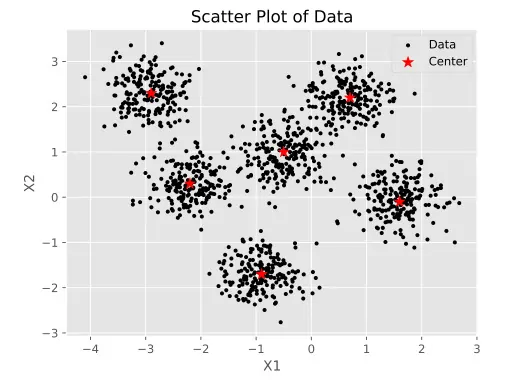
Küme sayısının ve merkezlerinin belirlenmesi
Yukarıdaki kodlarda, rastgele küme merkezlerini belirlemek için alt ve üst aralıkların değiştirilebileceğine dikkat edilmelidir. Üretilen verilerin iki boyutlu olduğu düşünüldüğünde kümelerin merkezleri de iki boyutlu bir ortamda konumlanacaktır.
Her veriyi bir kümeye atamak için bir işlev oluşturun
Bir sonraki adımda, kümelerin merkezlerinin koordinatlarını ve içindeki noktaları alan bir fonksiyon oluşturulmalıdır., her veri en yakın kümeye atanır ve son olarak her kümedeki bir veri dizisi döndürülür. Bu fonksiyon aşağıdaki gibi tanımlanır:
Her kümenin verilerini depolamak için bir liste oluşturun
Şimdi, nClusters kadar boş liste içeren bir liste oluşturulmalıdır, böylece daha sonra her veri o kümeye karşılık gelen listeye eklenir:
Yukarıdaki kodların çıktısında Cluster listesi aşağıdaki gibi olacaktır.
bensen=[[ ],[ ],…,[ ]]
Merkezden herhangi bir noktanın uzaklığını hesaplayın
Şimdi her veri için olmalıBen, her merkezden uzaklıkhesaplandı. Bunu yapmak için, önce tüm veriler üzerinde bir döngü oluşturun ve ardından her bir merkezin uzaklığını eklemek için boş bir dizi oluşturun.Bentanımlanmış
Bundan sonra tüm küme merkezleri için uzaklıkBene kadarhesaplanmış Bu şeyler aşağıdaki kodlarda yapılır:
Yukarıdaki kodlarda iki vektör çıkarılarakBenVebirbirinden almak(Ben,)L2 – Norm değerinin Öklid mesafesini ifade edeceği ortaya çıktı . Varsayılan olarak, norm işlevi L2 yöntemini kullanır . Tabii ihtiyaç halinde başka yöntemler de kullanılabilir. Artık verilmesi gerekiyorBenen yakın küme merkezine karşılık gelen listeye eklendi:
Bu sayede istenilen fonksiyon artık tamamlanmış olur ve gerekli fonksiyonu yerine getirir.
Küme listelerini dizilere dönüştürün
Sonunda, kullanımlarını kolaylaştırmak için Kümelerdeki listeleri dizilere dönüştürmek daha iyidir:
Artık oluşturulan işlevi programın ana metninde kullanabilirsiniz:
Python’da K-means algoritmasının tekrarlanan 3. ve 4. adımlarının uygulanması
“K-means nedir” yazısında bu noktaya kadar, K-means algoritmasının 1. ve 2. adımları tamamlanmış ve Python’da gerçeklenmiştir, şimdi 3. ve 4. adımların tekrarını gerçekleştirmek için, oluşturma ihtiyacı vardır. bir döngü:
Öncelikle küme merkezlerinin koordinatları her adımda güncellenmelidir. Bu işlem için aşağıdaki gibi bir fonksiyon tanımlanmalıdır:
Şimdi, her bir küme için karşılık gelen merkez, o kümenin ortalama noktalarına yerleştirilmelidir:
Bu nedenle değerler np.mean işlevi kullanılarak güncellenir. Bu aşamada önemli olan nokta eksen değeridir. Bu durumlarda eksen değeri sıfır olmalıdır ki ortalama alma işlemi satır başına değil, sütun başına yapılmalıdır. Bu bölümde ortaya çıkabilecek problem bir küme ile ilgili dizinin boş olmasıdır.
Böyle bir durumda ortalama değer hiçbir00gelecek, bu da programın uygulanmasını aksatacaktır. Bu nedenle, ilgili dizi boş değilse güncelleme işleminin gerçekleştirilebilmesi için bir koşul ayarlanmalıdır:
Bu şekilde merkezlerin güncellenmesi için gerekli fonksiyon oluşturulmuş olur. Şimdi oluşturulan döngünün tamamlanması gerekiyor:
Bu nedenle, K-means algoritmasının uygulaması Python’da yapılmıştır ve K-means algoritması doğru çalışacaktır.
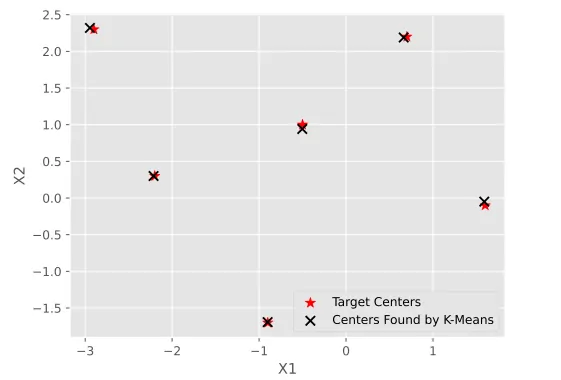
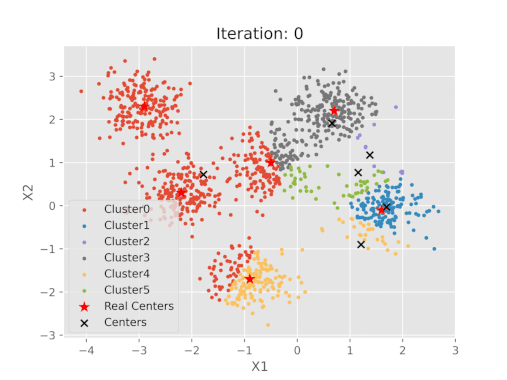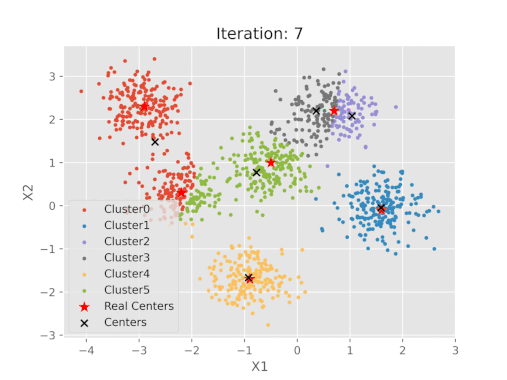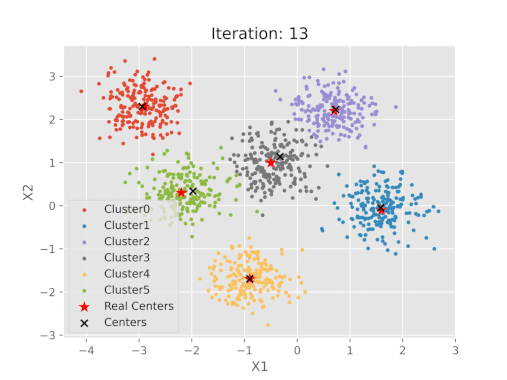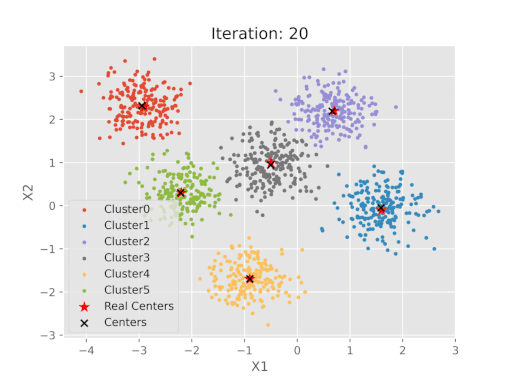
K-means algoritmasının uygulanan sonuçlarının gerçek küme merkezleri ile karşılaştırılması
Adımlar tamamlandıktan sonra K-Means algoritması sonucu ortaya çıkan merkezlerin koordinatlarını belirlenen merkezlerle karşılaştırmak mümkündür.
Yukarıdaki kodları çalıştırdıktan sonra çıktı görüntüsü aşağıdaki gibi olacaktır:

K-ortalama algoritma adımlarının görsel gösterimi

Çözüm
Bu yazıda öncelikle k-means algoritması nedir sorusuna cevap verilmiş ardından K-means algoritmasının Python‘da implementasyonu adım adım ve olabildiğince basit bir şekilde sunulmuştur. Bu uygulamada bunlara yönelik yapay üretim verileri ve küme merkezleri belirlenmiştir. Daha sonra K-ortalamaları gerçekleştirmek için gerekli kodlar ve fonksiyonlar oluşturulmuş ve bu algoritma üretilen veriler üzerinde çalıştırılarak sonuçları kümeler için belirlenen merkezler ile karşılaştırılmıştır.